NB通訊技術 物聯(lián)網(wǎng)領域多場景應用全解析
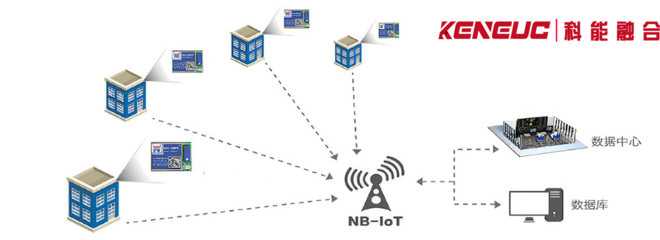
隨著物聯(lián)網(wǎng)(IoT)的快速發(fā)展,低功耗廣域網(wǎng)(LPWAN)技術成為連接海量設備的關鍵。在眾多LPWAN技術中,窄帶物聯(lián)網(wǎng)(NB-IoT)憑借其廣覆蓋、低功耗、大連接、低成本的核心優(yōu)勢,已成為推動物聯(lián)網(wǎng)規(guī)模化部署的重要引擎。本文將全面解析NB通訊技術在物聯(lián)網(wǎng)領域的多場景應用,展現(xiàn)其如何賦能千行百業(yè)的數(shù)字化轉型。
一、NB通訊技術核心優(yōu)勢
NB-IoT作為基于授權頻譜的蜂窩網(wǎng)絡技術,其核心設計理念完美契合了物聯(lián)網(wǎng)設備的典型需求。
- 深度覆蓋與廣連接:NB-IoT比傳統(tǒng)LTE網(wǎng)絡的信號覆蓋能力提升約20dB,可穿透地下車庫、地下室等信號難以到達的區(qū)域。一個基站小區(qū)可支持高達5萬至10萬個連接,為海量終端接入提供了可能。
- 超低功耗與長續(xù)航:NB-IoT終端在大多數(shù)時間處于深度休眠狀態(tài)(PSM或eDRX模式),僅在需要收發(fā)數(shù)據(jù)時被喚醒,使得終端設備依靠電池供電可持續(xù)工作數(shù)年甚至十年以上,極大降低了維護成本。
- 部署靈活與成本低廉:NB-IoT可直接部署于現(xiàn)有的蜂窩網(wǎng)絡基礎設施之上,支持平滑升級,建設與維護成本較低。其簡化的通信協(xié)議與低速率特點也降低了終端模塊的復雜度與成本。
二、多場景應用全景解析
NB-IoT的技術特性使其在眾多對成本、功耗、覆蓋要求嚴苛的場景中脫穎而出。
1. 智慧城市
智慧城市是NB-IoT應用最廣泛、最成熟的領域之一。
- 智慧抄表:水表、燃氣表、電表等通過內(nèi)置NB-IoT模塊,實現(xiàn)數(shù)據(jù)的自動、定時、遠程回傳,徹底解決了人工抄表效率低、誤差大、入戶難的問題,為階梯計價和資源精細化管理提供數(shù)據(jù)支撐。
- 智能停車:地磁車位檢測器通過NB-IoT上報車位占用狀態(tài),結合手機APP,實現(xiàn)車位查詢、導航、無感支付,有效緩解城市“停車難”。
- 智慧路燈:每一盞路燈成為物聯(lián)網(wǎng)節(jié)點,實現(xiàn)單燈控制、按需調光、故障自動報警,節(jié)能率可達30%-60%。
- 環(huán)境監(jiān)測:部署于各處的NB-IoT傳感器可實時監(jiān)測空氣質量(PM2.5等)、噪聲、水質等環(huán)境數(shù)據(jù),為城市環(huán)境治理提供精準依據(jù)。
2. 智慧農(nóng)業(yè)
NB-IoT為精準農(nóng)業(yè)和農(nóng)場智能化管理提供了經(jīng)濟可行的解決方案。
- 智能灌溉:土壤溫濕度、光照傳感器數(shù)據(jù)通過NB-IoT上傳至云平臺,系統(tǒng)自動分析并控制閥門進行精準灌溉,節(jié)約水資源,提升作物產(chǎn)量。
- 畜牧養(yǎng)殖:為牲畜佩戴NB-IoT項圈,可實時監(jiān)測位置、體溫、活動量,實現(xiàn)電子圍欄、疫病預警和資產(chǎn)追蹤。
3. 智能家居與建筑
在樓宇和家庭內(nèi)部,NB-IoT為各類設備提供了穩(wěn)定可靠且無需復雜組網(wǎng)的連接方式。
- 智能安防:煙霧報警器、燃氣探測器、門窗磁傳感器等在探測到險情時,通過NB-IoT網(wǎng)絡第一時間向用戶和物業(yè)中心發(fā)送警報,保障生命財產(chǎn)安全。
- 能耗管理:對樓宇內(nèi)的空調、照明等設備進行聯(lián)網(wǎng)監(jiān)控與智能控制,實現(xiàn)建筑整體節(jié)能。
4. 資產(chǎn)追蹤與物流
NB-IoT的廣覆蓋和低功耗特性特別適合移動或分布廣泛的資產(chǎn)監(jiān)控。
- 物流追蹤:在物流集裝箱、托盤或高價值貨物上安裝NB-IoT定位跟蹤器,實時監(jiān)控位置、運輸軌跡及溫濕度狀態(tài),保障運輸安全與質量。
- 共享經(jīng)濟:共享單車、共享充電寶等通過內(nèi)置NB-IoT鎖具或通信模塊,實現(xiàn)開鎖、計費、定位和狀態(tài)上報。
5. 可穿戴設備與健康醫(yī)療
在健康監(jiān)測領域,NB-IoT提供了始終在線、無需頻繁充電的連接方案。
- 老人/兒童看護:智能手環(huán)或定位器可實時上報位置和心率等健康數(shù)據(jù),并在發(fā)生異常(如跌倒、離開安全區(qū)域)時自動告警。
- 遠程醫(yī)療監(jiān)測:慢性病患者佩戴的便攜式監(jiān)測設備(如血糖儀、血壓計)可將數(shù)據(jù)通過NB-IoT直接傳輸給醫(yī)生,便于長期跟蹤和遠程指導。
三、挑戰(zhàn)與未來展望
盡管NB-IoT發(fā)展迅猛,但仍面臨一些挑戰(zhàn),如不同運營商網(wǎng)絡覆蓋質量差異、模組成本進一步下探空間、以及與5G NR-Light(RedCap)等新興技術的協(xié)同與演進關系。隨著5G-A(5G-Advanced)技術的推進,NB-IoT將與更高速率的物聯(lián)網(wǎng)技術(如Cat.1, RedCap)形成互補的協(xié)同網(wǎng)絡,共同服務于從低速到中高速的全場景物聯(lián)網(wǎng)需求。與人工智能、邊緣計算的融合,將使NB-IoT終端從“數(shù)據(jù)管道”進化為具備初步智能的“感知節(jié)點”,推動物聯(lián)網(wǎng)應用向更智能、更自主的方向發(fā)展。
總而言之,NB通訊技術作為物聯(lián)網(wǎng)的“毛細血管”網(wǎng)絡,已深度融入經(jīng)濟社會發(fā)展的方方面面。其對多場景的賦能,不僅提升了各行業(yè)的運營效率和管理水平,更催生了全新的商業(yè)模式和服務體驗,正持續(xù)為萬物智聯(lián)的數(shù)字世界奠定堅實的連接基石。
如若轉載,請注明出處:http://www.beijingportal.com.cn/product/51.html
更新時間:2026-06-18 04:44:55